
前言
问 题: 最近准备训练一个基于对比学习的模型, 用 huggface 的 trainer 训练器,在官方给的源代码中,有一个现成的 sampler 用于数据采样,我需要改写这个 sampler 以保证能够用于自己的数据上。
实验
改完之后,发现采样出来的 indices 竟然是有序的,实际在一个批次中需要打乱样本的顺序,仔细阅读了官方给的源码,发现问题出在如下图所示的 第187行。这里先用 torch.randperm生成了一个乱序的下标,然后转换为set。按理说set是无序的,转换之后也是无序的,看起来很正确。
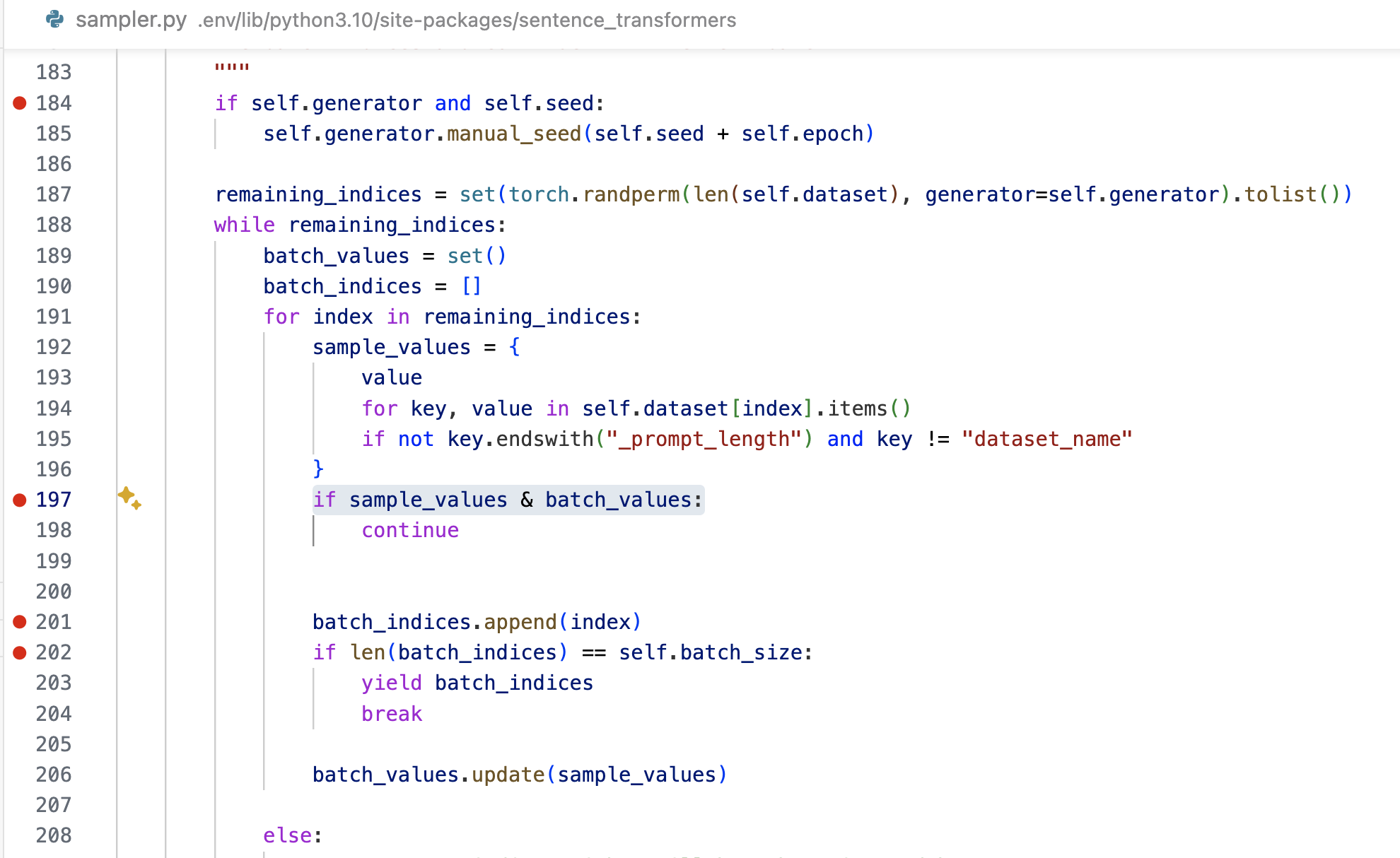
当我做了小测试后,发现并不是:

从上面的结果,可以看到:torch.randperm() 生成的序列是乱序的,但经过 set() 处理之后似乎变成了有序。
我们又做了一组测试: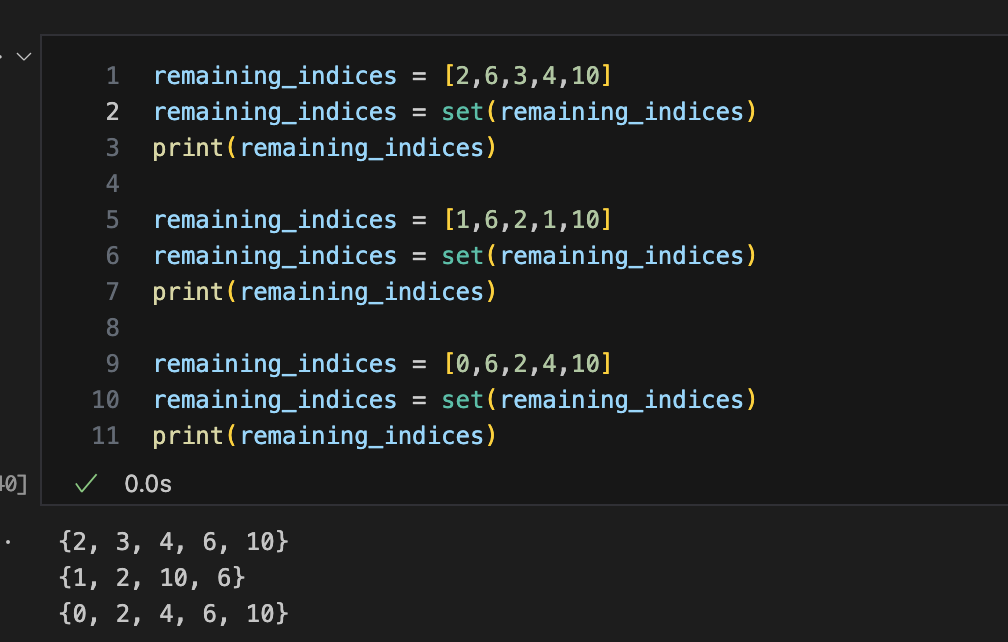
可以看到:当list中的元素全部是数字,且没有重复值的时候,set()出来后的序列变成了有序,而中间的那个试验,序列是无序的。
所以很多python的教程说set的无序的,这点并不具体。更加具体的说法应该是:set是一个集合,它没有序惯性质,如果任务要求的数据结构需要包含元素的序列,则不能采用set作为数据结构。上面的bug就是一个错误例子。
后续
我检查了一下所使用的库是最新版,找到了官方的github地址,准备提交issue。才发现官方2个月前就已经在github源码中修改这个 bug,但是由于依赖原因,并没有提交到代码仓库。下面是修改后的版本的关键代码(关键代码在190行):
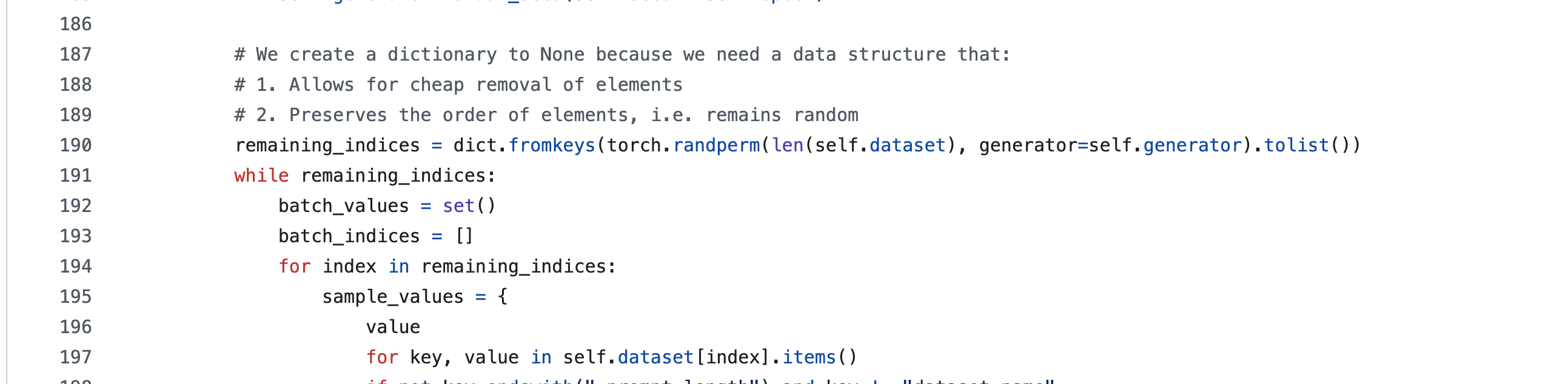
小结一下: 这是一个非常隐蔽的bug,如果不是因为我要实现自己的sampler,一定不会发现不同epoch中相同的batch的下标是一样的,所以说当模型性能不够好的时候,可以去溯源一下代码,看看具体的代码实现是否和自己所设想的一致。