
Hugging face是一个专注于NLP的公司,拥有一个开源的预训练模型库 Transformers ,里面囊括了非常多的模型例如 BERT GPT 等.
模型库
官网的模型库的地址如下:https://huggingface.co/models
使用模型
首先需要安装transformers库,使用以下命令安装:
1 | pip install transformers |
接下来在代码中调用 AutoTokenizer.from_pretrained 和 AutoModel.from_pretrained 即可, 例如:
1 | from transformers import * |
运行后系统会自动下载相关的模型文件并存放在电脑中。使用Windows模型保存的路径在 C:\Users[用户名].cache\torch\transformers目录下,根据模型的不同下载的东西也不相同
使用Linux模型保存的路径在 ~/.cache/torch/transformers/ 目录下。
存在的问题
这些前提是你的电脑有网络可以直接使用代码下载相应的模型文件,但是问题是有些机器是没有外网连接权限或者下载速度非常慢。
这时候就需要把模型文件下载后在导入代码中,还是以刚才的 hfl/chinese-xlnet-base 模型为例,直接在官网搜索模型,点击进入模型的详情界面

在界面中找到 Files
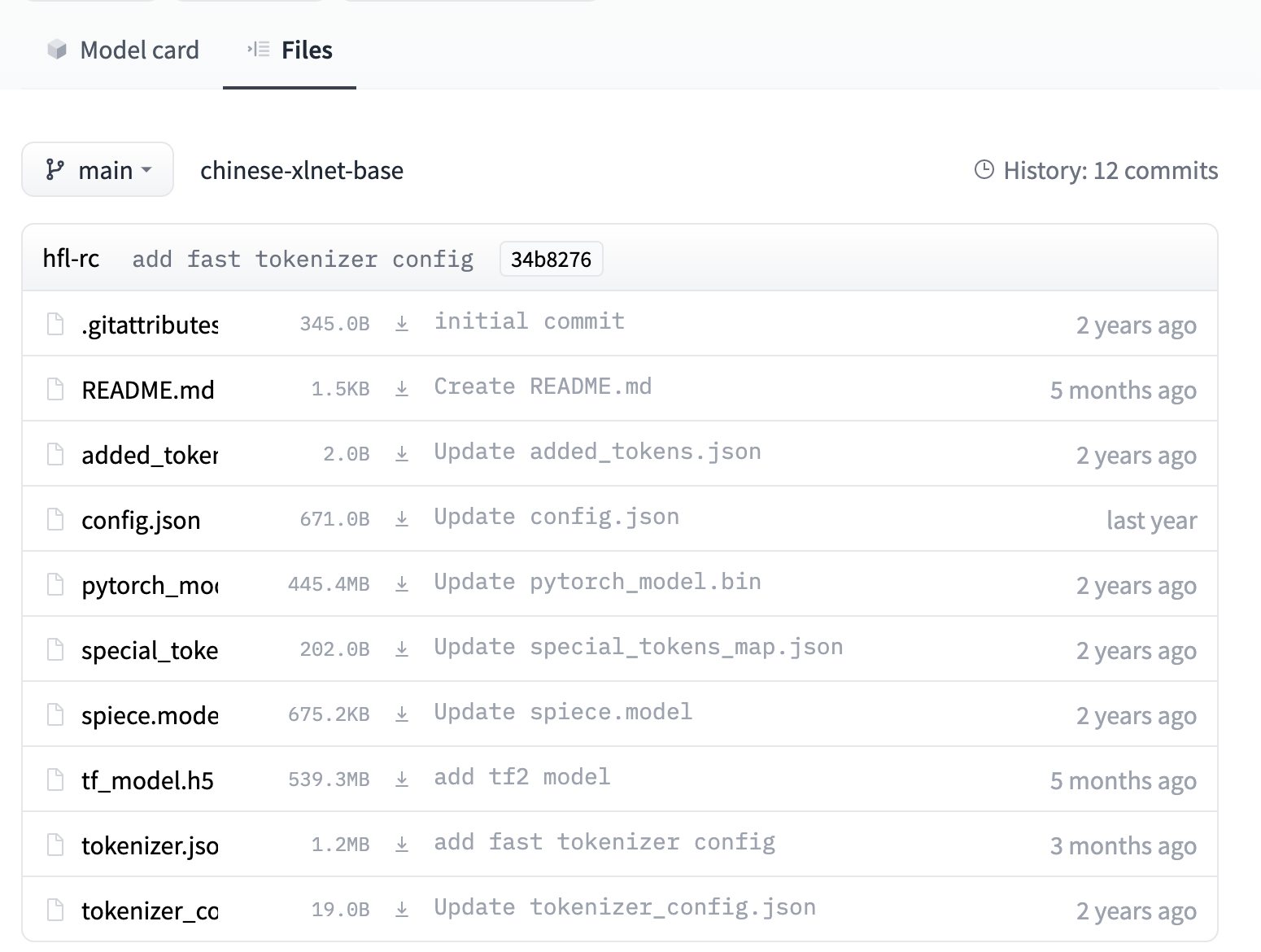
把弹窗内的文件全部下载下来
我们假设文件保存在 E:\models\hfl\chinese-xlnet-base\ 目录下
我们只需要把model_name 修改为下载的文件夹即可
1 | from transformers import * |
这样问题就解决了。